深偽內容(Deepfake)
隨著近年來深度學習技術與相關生成模型的快速發展,多媒體(包括影像、聲音、文字)內容生成系統效能大幅提升,著名的方法如NVIDIA的StyleGAN(Karras et al. 2019、Karras et al. 2021)和GauGAN(Park et al. 2019)。能做出高仿真內容偽造已經不僅侷限於熟悉多媒體編輯軟體的創作者,普羅大眾也能透過網路上各式基於深度生成模型,如生成對抗網路(Generative Adversarial Network)之開源軟體輕易修改圖片、聲音、與文字等數位內容,如使用DeepFace Lab與FaceApp等軟體(FaceApp, 2021、FaceSwap, 2021、DeepFaceLab, 2021)。最早「深偽」(Deepfake)是一套在美國網路論壇(Reddit)流傳,專門用來替換影片中人臉來製作色情影片的軟體名稱,目前已經成為這類利用深度生成技術對影像、聲音、文字等多媒體內容進行編輯等操作生成之內容總稱。內容操作包括臉部特徵變換、性別與年齡轉換、圖像風格轉換或超解析度等各式影像,或其他模態數位內容特效編輯,如圖一(a)和(b)所示。
愈來愈多手機程式和開源軟體內建這些功能,一般大眾可以非常容易接觸和使用這些技術,輕鬆透過幾個簡單的操作就可進行傳統需要複雜步驟的多媒體內容的編修。隨著內容偽造的門檻大幅降低,這類深偽技術也可被有心人士用於大量製作偽造的名人色情影片,如去年底引起社會各界關注的網紅換臉事件。透過深偽技術可以把影片的人臉置換成任何我們想要的人臉,並做指定的表情等動作,或用於生成假新聞,假帳號和進行詐騙。例如Facebook跟Instagram曾多次發現不少使用深偽技術自動生成的照片申請的人頭帳號、粉絲專頁與社團,進行詐騙或散播敏感言論。真實案例如英國一間能源公司的CEO,因為接到德國母公司上司一通電話,要求他緊急將780萬台幣匯至指定供應商帳戶,該CEO自認對於上司聲音相當熟悉,所以接到電話之後不疑有它,就派人去轉帳了(News 2019-1),但上司的聲音是透過聲音轉換(Voice Conversion)的技術偽造的。隨著不斷推陳出新的深偽模型,導致詐騙層出不窮,儘管有些生成的影像和聲音的品質不佳,但在手機上撥放,由於屏幕的大小和解析度有限,使用者仍難判斷其內容是否被動過手腳,傳統的眼見為憑不再一定為真,也需要社會各界對相關深偽議題有更深的認識。
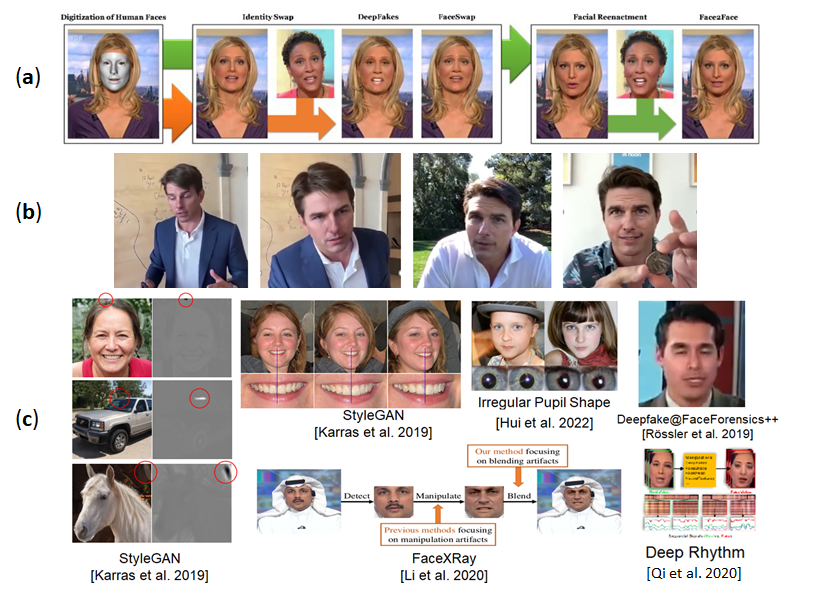
圖一、
(a)透過深度造假的技術來修改人臉:換臉、人臉微調,其中如圖所示。影像來源:Rössler et al. 2019。
(b)明星Tom Cruise的深偽影片品質之高,真假難辨。影像來源:Chris Ume and Miles Fisher, 2021。
(c)各種不同的深度生成模型的瑕疵,如深偽生成的人臉其牙齒不會跟著頭擺動、或瞳孔不是橢圓形、影像或人臉接合處有明顯的瑕疵。影像來源:Rössler et al. 2019、Karras et al. 2019、Hui et al. 2022、Qi et al. 2020。
深偽偵測與其他可能的反制手段
隨著深度造假的技術不斷進化,偽造內容的氾濫有可能會演變成不可忽視的資訊安全危機,有鑒於此,美國DARPA早在2016年即開始Media Forensics研究計畫,開發關鍵技術以遏止相關多媒體偽造內容的氾濫。同時DARPA也計畫在2020年中開啟Semantic Forensics研究計畫,計畫讓機器能了解圖像及影片中,所蘊含的語意,做出更精準的偽造內容辨識和事件偵測。而臉書(Meta)、谷歌(Google)、微軟(Microsoft)等大公司持續投入大量資源於相關鑑識研究,臉書在2020年時,曾舉辦總獎金高達100萬美元的深偽偵測競賽,吸引全球超過300個隊伍報名參加,由此可見相關研究的重要性與日俱增,並逐漸獲得各界的關注。而深偽偵測是目前最熱門的防禦方法之一,以深偽影像為例,如果要偵測數位內容是否被竄改,最簡單的方式,可以透過監督學習的方式,收集包含深偽影像和正常影像的訓練資料,並使用深度學習或其他機器學習模型建立一個「二元分類器」(Binary Classifier),將任何輸入圖像影片分為兩類:真實或偽造。但因為深偽演算法不斷快速推出新的模型,此類方法需要收集大量深偽資料以盡可能包含各種情況,不僅收集與標註費時費力,實務上執行也有相當的困難度。
因此,也有研究著重於探索深度生成模型的生成極限,如目前深偽技術生成的影片仍存在一些視覺瑕疵或不符合常理,可供辨識和偵測之用,很多研究則利用這些瑕疵以設計泛化能力強的偵測模型,常見的瑕疵如圖一(c)所示,生成的圖像影片裡是否背景區域模糊、人臉區塊有沒有閃爍(尤其是眼睛部分,人的瞳孔是橢圓形,但生成模型生成的瞳孔通常為不規則,而且雙眼看到的事物不一致)、臉部輪廓邊緣的紋理是否自然、接合處是否有明顯瑕疵、影片跨幀時臉部輪廓或紋理是否有失真,或講者在有大幅度移動動作時其影像紋理是否正常等視覺瑕疵。另外,像某些深偽技術,並沒有辦法讓說話者的聲音與嘴部影像達到十分吻合與同步,因此,可以透過逐禎檢驗影像與對應音檔,看看是否有地方是不吻合的。因為目前深偽造假技術還沒辦法做到同時模仿一個人的表情與聲音情緒,我們也可以透過檢驗聲音中的情緒,以及他的面部表情是否吻合來辨別真偽。而深偽影片要達到良好的生成品質也需要大量的資料,所以名人等擁有較多公開影片資料,等同提供深偽算法的豐富素材,我們可將將較有名的名人建立一個字典,針對特定的新聞文章或影片字幕中有出現這些名人,則我們應考慮到可能會有被進行深偽造假的可能,並進一步對可疑新聞影片作分析,如此一來也可以從海量待偵測的數據當中先篩選出一些較可能被造假的素材。除了深偽偵測的防禦手段,也有相關研究透過對抗樣本(Adversarial Example)攻擊(GoodFellow et al. 2014),在輸入訊號添加人眼不可見的擾動,這些對抗樣本可以對基於深度學習模型的輸出產生巨大影響,以產生錯誤的辨識結果,我們可以反利用這種攻擊讓深偽生成模型的生成影像和語音品質大幅下降或不起作用,進而保護內容不被盜用(Ruiz et al. 2020、Yeh et al. 2020、Yeh et al. 2020),如圖二(a)所示。另一方面,在影片內容添加不可視數位浮水印,讓內容擁有者或普羅大眾可以更有效地透過內嵌的浮水印訊息以判斷內容的真偽,其中有相關研究透過在訓練資料添加隱形數位浮水印(Yu et al. 2021),讓用這些資料訓練的深偽生成模型,其生成的內容都包含浮水印,透過抽取浮水印即可辨別內容真偽,如圖二(b)所示。
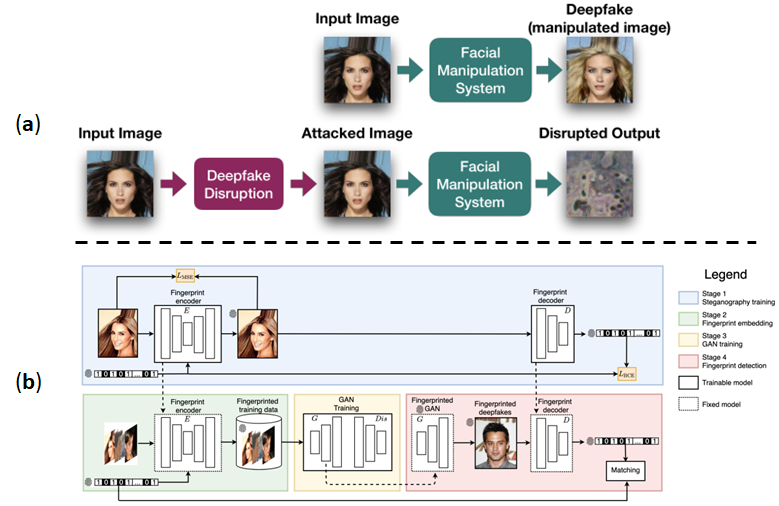
圖二、
(a)產生對抗樣本讓影像遷移模型生成影像壞掉。影像來源:Ruiz et al. 2020。
(b)基於隱形數位浮水印之深偽內容追蹤與驗證系統架構圖,在訓練資料每張圖像添加二元字串浮水印。影像來源:Yu et al. 2021。
未來的挑戰
目前基於深度學習之深偽偵測器,儘管對已知深偽算法所產生的內容,有非常好的性能,但對於訓練資料未出現過的深偽內容,尤其是由新的深偽演算法生成的內容,其偵測效果常大打折扣,因為模型過擬合訓練資料導致,最簡單的解決方法是依賴收集更大量的訓練數據來訓練更強深偽偵測器,但這種作法不僅使得維護和收集這樣的訓練數據集變得非常困難,也很難應對不斷快速推陳出新的深偽演算法。另一方面,因為新的深偽算法剛推出的時候,其生成內容一開始在網路上曝光還不夠多,可收集和供訓練利用的資料數量不多。因此,如何僅用少量的資料有效訓練深偽偵測器或是泛化能力更強的模型,是一個非常挑戰且亟待解決的研究問題,或是如何利用多模態資料間的相關性(視覺、文字、相片標註資料等),建構資料間的關係圖,並以此來驗證資訊的正確性,也是多媒體鑑識研究(Multimedia Forensics)中需要研究繼續挑戰的課題。
而其他防禦方法如基於深度學習之不可視數位浮水印,其可嵌入的信息量仍有限制,現行研究主要嵌入二元字串,但二元字串是否可以足夠當作來源影片與內容擁有者的憑證,是亟待解答的問題,因此,當務之急是要如何改進架構,增加可嵌入的信息量,如此,可以考慮除了二元字串以外的憑證,如QR code、或數位印章等憑證。浮水印對於不同影像操作的強健性,尤其是未知的操作,大部分浮水印經過操作會損失大量訊息,如何在不同影片編輯操作下,保存足夠資訊供來源追蹤或內容驗證,也是一大挑戰。而目前深偽內容,影片佔大宗,基於深度學習之數位浮水印研究仍以影像為主,如何設計快速有效的影片數位浮水印,仍是一大難題。同樣地,目前基於對抗樣本的防禦方法主要也仍是以單張影像為主,影片的對抗樣本需要考慮幀與幀之前的連續性與一致性,才不會讓添加的對抗擾動嚴重影響影片原來的品質,並保持足夠的攻擊能力讓深偽生成模型無效,需要更深入的研究‧目前有的攻擊模型主要仍是針對已知的生成模型進行白盒攻擊,對於未知模型,需要設計有效的黑盒攻擊模型,如何確保對抗樣本攻擊的可遷移性,則是另外一項挑戰。
參考文獻
[News 2019-1]https://qz.com/1699819/a-new-kind-of-cybercrime-uses-ai-and-your-voice-against-you/
[Yu et al. 2021]Yu, Ning, Vladislav Skripniuk, Sahar Abdelnabi, and Mario Fritz. “Artificial fingerprinting for generative models: Rooting deepfake attribution in training data.” In IEEE/CVF International Conference on Computer Vision (CVPR), pp. 14448-14457. 2021.
[Ruiz et al. 2020] Ruiz, Nataniel, Sarah Adel Bargal, and Stan Sclaroff. “Disrupting deepfakes: Adversarial attacks against conditional image translation networks and facial manipulation systems.” In European Conference on Computer Vision (ECCV), pp. 236-251. Springer, Cham, 2020.
[Khalid et al. 2021] Khalid, Hasam, Shahroz Tariq, Minha Kim, and Simon S. Woo. “FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset.” arXiv preprint arXiv:2108.05080 (2021).
[Yeh et al. 2020] Yeh, Chin-Yuan, Hsi-Wen Chen, Shang-Lun Tsai, and Sheng-De Wang. “Disrupting image-translation-based deepfake algorithms with adversarial attacks.” In IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), pp. 53-62. 2020.
[Yeh et al. 2021] Yeh, Chin-Yuan, Hsi-Wen Chen, Hong-Han Shuai, De-Nian Yang, and Ming-Syan Chen. “Attack as the Best Defense: Nullifying Image-to-image Translation GANs via Limit-aware Adversarial Attack.” In IEEE/CVF International Conference on Computer Vision (ICCV), pp. 16188-16197. 2021.
[GoodFellow et al. 2014] Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. “Explaining and harnessing adversarial examples.” arXiv preprint arXiv:1412.6572 (2014).
[Karras et al. 2019] Karras, Tero, Samuli Laine, and Timo Aila. “A style-based generator architecture for generative adversarial networks.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4401-4410. 2019.
[Karras et al. 2021] Karras, Tero, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. “Alias-free generative adversarial networks.” In Neural Information Processing Systems (NeurIPS). 2021.
[Rössler et al. 2019] Rossler, Andreas, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. “Faceforensics++: Learning to detect manipulated facial images.” In IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1-11. 2019.
[FaceApp 2021] https://www.faceapp.com/
[DeepFaceLab, 2021] https://github.com/iperov/DeepFaceLab
[FaceSwap, 2021] https://faceswap.dev/
[Chris Ume and Miles Fisher, 2021]https://www.today.com/news/man-tom-cruise-deepfakes-tiktok-speaks-ethics-technology-rcna10163
[Li et al. 2020] Li, Lingzhi, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Baining Guo. “Face x-ray for more general face forgery detection.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5001-5010. 2020.
[Hui et al. 2022] Guo, Hui, Shu Hu, Xin Wang, Ming-Ching Chang, and Siwei Lyu. “Eyes Tell All: Irregular Pupil Shapes Reveal GAN-generated Faces.” In International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2022.
[Park et al. 2019] Park, Taesung, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. “GauGAN: semantic image synthesis with spatially adaptive normalization.” In ACM SIGGRAPH 2019 Real-Time Live!, pp. 1-1. 2019.