為推廣科普知識,本院自94年起,每年定期推薦本院院士或研究人員至高中演講,與年輕學子交流互動,以深入淺出的方式分享學術研究成果。
今(110)年4月7日,本院統計科學研究所楊欣洲研究員受邀前往臺南一中,擔任竹園學術講座主講人,主講「大數據科學讓新冠病毒現形」,由該校一年級徐兆廷同學撰寫側記及心得,內容如下:
在COVID-19疫情肆虐全球下,許多國家分別研發疫苗,但隨著疾病的傳播與流行,病毒開始出現各種變異並產生不同的基因體、生物特徵、型態。而楊研究員說明他與研究團隊是如何運用大數據科學(Big data analysis)將病毒分類、追蹤,並應用此技術。
(一)為何需要利用大數據科學分析和追蹤新冠病毒?
新冠病毒的遺傳物質為RNA,且容易發生突變。在世界各地傳播時會產生各種不同的突變種如:南非變種、英國變種等,而不同的變種有不同的基因,因此有不同的生物特徵或構造,進而造成在群體中傳染力、致死率及症狀不同的影響。
以在群體中的傳染能力為例,病毒侵入細胞時,仰賴病毒表面特異性高的刺突蛋白(Spike protein)與細胞表面的血管收縮素轉化酶2(Angiotensin-converting enzyme 2, ACE2)結合(圖一),也就是將ACE2作為受體侵入細胞(圖二)。藉由此方式,製造類似於病毒刺突蛋白之物質,促使免疫反應發生,並引起專一性防禦,即疫苗的作用方式。而當病毒發生變種時,其刺突蛋白可能因此改變,而降低先前注射之疫苗所造成的專一性防禦功效。
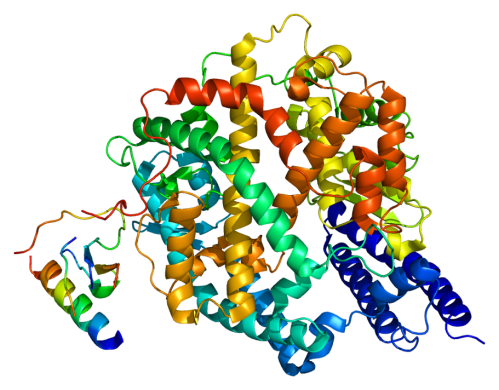
圖一:血管收縮素轉化酶2(Angiotensin-converting enzyme 2, ACE2)
資料來源:Wikipedia. Structure of the ACE2 protein. (Dec.15, 2009)
Retrieved from https://en.wikipedia.org/wiki/File:Protein_ACE2_PDB_1r42.png
{kind=link}
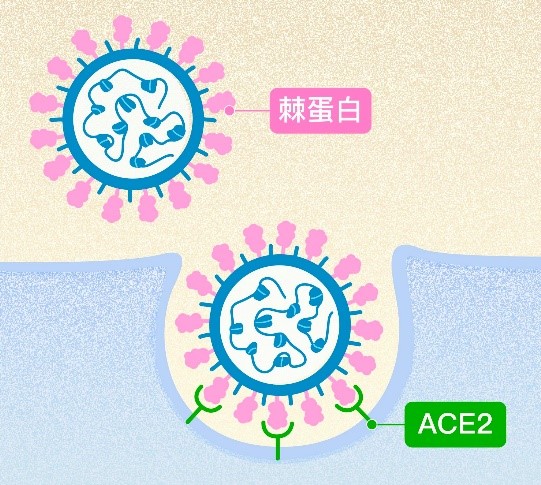
圖二:新冠病毒侵入細胞過程
資料來源:「研之有物」https://research.sinica.edu.tw/covid19-p3lab-academiasinica/
故相同的疫苗對於不同的變種病毒在人體上的功效具有差異,需藉由病毒的刺突蛋白設計疫苗,才能達到最佳的療效。因此才須將新冠病毒進行分類,以利追蹤與製造疫苗,而大數據分析恰為妥當分析變種病毒間的親緣關係與演化歷程,方便進行病毒變種追蹤與類別分析。
(二)如何取得分析新冠病毒之資料庫?
分析前,其中一項關鍵要素為建立資料庫。新冠肺炎病毒是RNA病毒,故其遺傳密碼由四種鹼基組成,分別為腺嘌呤(Adenine, A)、脲嘧啶(Uracil, U)、鳥嘌呤(Guanine, G)、胞嘧啶(Cytosine, C)構成。新冠病毒的遺傳序列中共有約30,000個鹼基。當世界各地的醫生在病患身上採檢後,將病毒的遺傳物質定序,並經過篩檢後上傳至全球共享流感數據倡議組織(GISAID),以公開來自世界各地的病毒序列資訊,使不同實驗室皆能進行病毒序列分析。在疫情爆發最初,僅有約1,000組病毒序列,而隨著疫情蔓延,至今已累計超越一百萬組病毒序列可供分析,使資料庫更加齊全。
(三)如何比較病毒親緣關係、歸類及建立演化樹?
首先,科學家將在中國武漢採取到的最初病毒序列訂為武漢一號,將其他病毒30,000個鹼基與其逐一比較,將不同者列為1,相同者列為0。則每一則病毒序列可得30,000個不同的變數。而累計至今的資料庫,該資料將變為矩陣,將其矩陣視覺化(圖三),每類型中的直線為不同病毒株間相同某特定基因變異造成,並可分類出六大類病毒。如同在下圖之中可知第五類病毒擁有共同的遺傳特徵是編號1397與編號11083與28688之鹼基發生變異;而第四類病毒則是擁有在編號8782、17747、17858、18060、28144之鹼基遺傳變異所致。
將1,932株病毒株依據其基因序列建立親緣關係樹,並將親緣關係樹與已視覺化之矩陣合併後,發現兩者結果十分吻合。而依照兩者互相比對即可作為辨識突變種之依據,可明確歸類出六大類新冠病毒突變種及其亞種(圖四)。如在第六型突變種中可發現變異鹼基編號1059、25563的亞變異種和變異鹼基編號28881、28882、28883的亞變異種,但除此之外仍有許多不同病毒株具有相同的鹼基變異,卻未被歸類為某亞種,是由於亞種的分類仍較依靠親緣關係樹的辨識。

圖三:Variation matrix map and viral strain type.(Yang. et al 2020)
但在分析資料時,楊研究員與其團隊面臨了資料量過大的困難。國家高速網路與計算中心無法分析38,248*30,000之矩陣,而楊研究員則利用直接比對某特定基因(如上述可鑑定種類的基因,即上圖中不同基因為所連成的直線),以及基因序列間兩兩比對以減少計算量。在得到幾乎相同的研究效果前提下,大幅度降低了分析時間。透過使用不同的分析方式,儘管分析樣本數增加,分析時間仍降低(表一)。
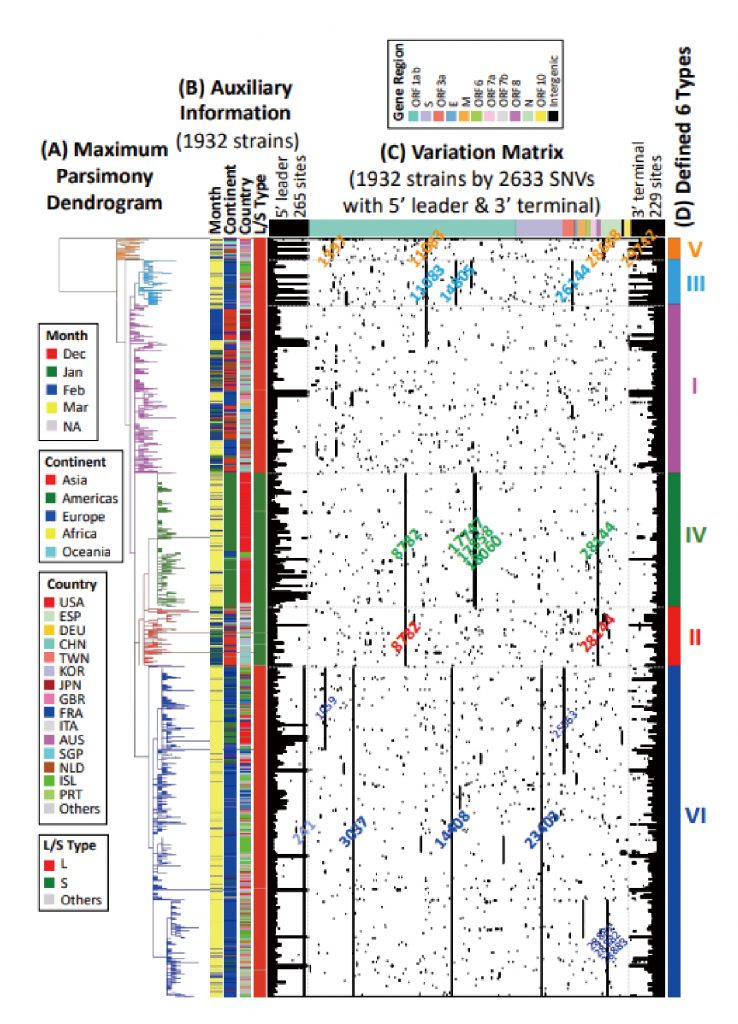
圖四:Maximum parsimony dendrogram, variation matrix map and defined six types for 1,932 SARS-CoV-2 viral strains.(Yang. et al 2020)
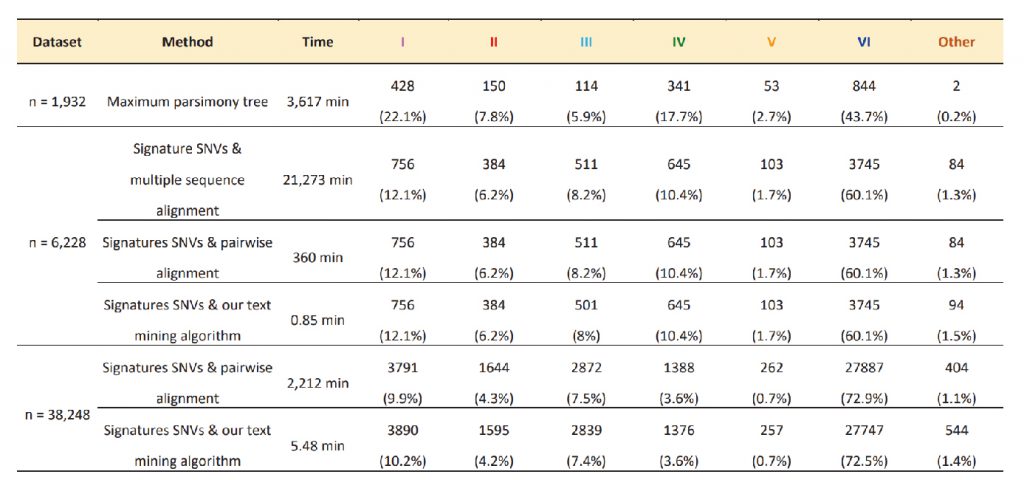
表一:Number and proportion of the SARS-CoV-2 strains in our defined six types.(Yang. et al 2020)
(四)目前世界盛行哪一類型突變種,以及其基因特徵?
由圖五可知,世界各地目前主要以第六型為主。而其他類型的病毒在爆發初期皆可見,但由於第六型具有更強的生存優勢,如:較強的傳染力,因此目前世界所盛行的皆為第六型突變種(圖中藍線)。
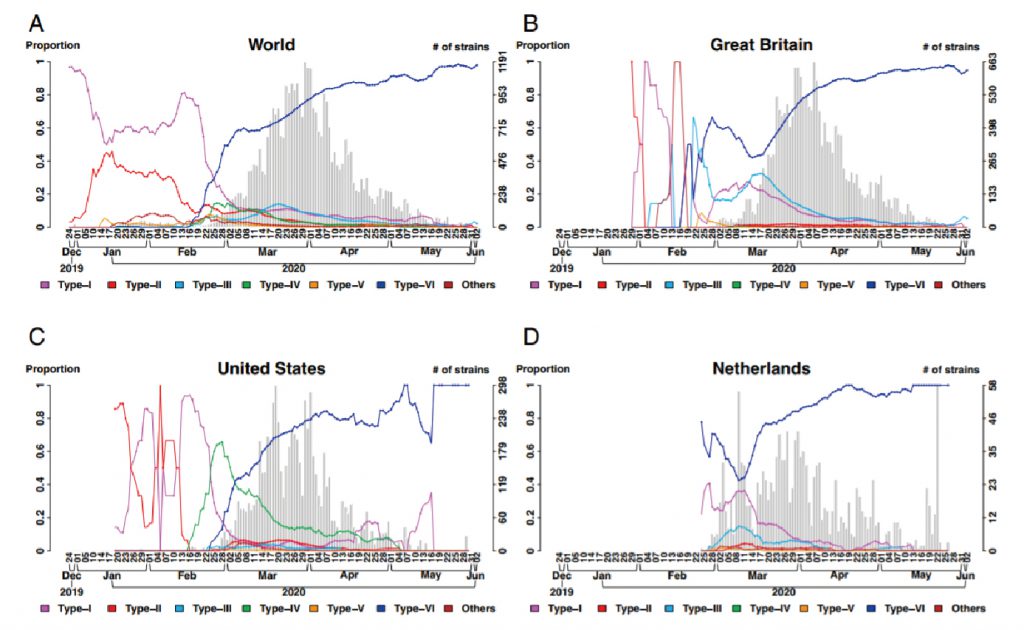
圖五:Temporal distributions of the six types.(Yang. et al 2020)
心得
楊欣洲研究員的演講十分精彩,讓我收獲許多。不過讓我最印象深刻的是了解跨領域人才的重要性,尤其當代有許多複雜的科學問題,例如新冠病毒的研究,更需要不同領域的科學家共同努力,才能從不同面向解析問題。其中,楊老師擅長統計,使用GISAID的資料,是上傳自世界各地能進行病毒基因序列分析的實驗室,若沒有這些不同領域的專家互助合作,應無法單方面解決問題。
演講中也讓我領悟在解決跨領域問題時,需具有基本的不同領域的基本知識,如同楊老師必須得知病毒的基因序列與其突變模式,方能改良分析方法。因此,這場演講讓我更加相信,應勇於在不同領域多所涉略學習,並整合各科所學習到的知識,為研究科學問題打好根基。