人工智慧技術能夠自動生產藝術作品的說法已經不是新聞。根據研究,深度神經網路模型已能有效地模仿梵谷的筆觸、巴哈的對位、李杜的詩句,但這代表人工智慧技術已經取代藝術家了嗎?深度神經網路模型有可能用來創作一齣電影,或執行一場現場的音樂會表演嗎?有關大規模而需要團隊高度分工的藝術製作,人工智慧又適合扮演什麼樣的角色?不可否認的是,人類進行藝術創作的複雜行為、鑑賞作品的多樣視角,仍遠非當今人工智慧技術所盡能達致。人工智慧技術即使能「模仿」現成的藝術作品,距離「取代」人類仍有很大一段距離,而如何讓人工智慧「輔助」需要精緻分工的文化藝術相關產業,則是值得發展的方向。本文將聚焦於此,特別討論人工智慧在音樂與多媒體產業中的應用。
多媒體產業的人工智慧化確實是一項細膩的工程,其往往關係到影像、聲音、乃至於情感與體感層面等多模態 (cross-modal) 資料的整合。例如:在動畫的製作和展演過程中,為求視覺聽覺元素之完美搭配,往往需要眾多製作者費心合作,此時標準化的內容生產工具可望大幅增進其製作效率。此外,當代藝術工作者們勇於探索虛擬與實體世界的邊界,其中人機共創、人機共演之音樂、舞蹈等表演藝術內容也是不斷嘗試的創意形式。這些需求反映了當今人工智慧技術在圖像、音樂與文字生成上的限制:這些技術大多限於非互動、單一資料類型的內容生成,而無法處理製作者、表演者與觀眾之間多向的互動機制,以及前述影像、音訊、語意等多模態訊號的溝通、轉換與競合過程。
本實驗室的虛擬音樂家系統,便是為了處理這些難題。想像一場人類和虛擬音樂家共同演出的音樂表演,其中虛擬音樂家能自動理解音樂內容,跟隨著人類詮釋音樂的速度,並根據音樂內容做出相對應的肢體動作,與各種也是從音樂自動生成的舞臺效果一起呈現。此節目的製作人僅需指定表演曲目,虛擬音樂家的表演內容即可自動產生,而舞台上的人類和虛擬音樂家也僅須透過音樂即可互動。為了達到這樣的互動和分工,製作端必須掌握兩項關鍵機制:一、基於劇本的虛擬演奏者的肢體動作、聲音乃至於視覺效果的自動生成機制;二、真人與虛擬音樂家演出內容之同步與校正機制。換句話說,我們希望打造一個源於音樂,也歸於音樂的多媒體內容創造機制:只需指定曲目,虛擬音樂家即可自動與人類練習並完成帶有視覺效果的演出。我們的虛擬音樂家系統因此包含三項技術:自動伴奏、音樂-肢體動作生成、音樂-視覺風格轉換。以下將分別簡介此三種技術。
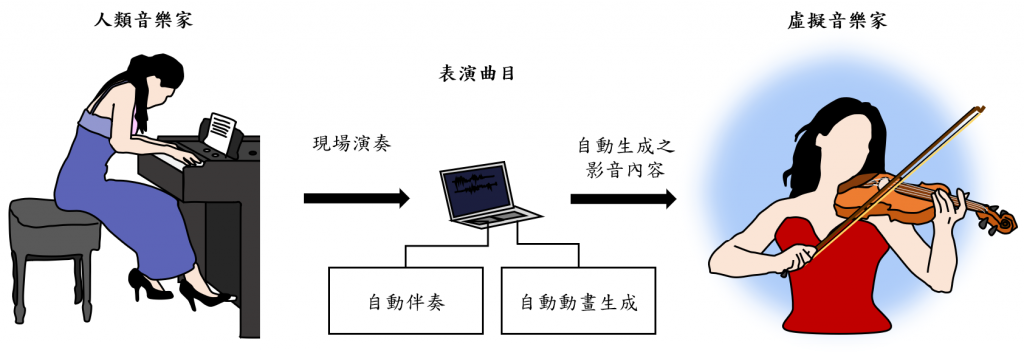
圖:虛擬音樂家系統示意圖。
自動伴奏
在音樂表演上,人類和機器藉由音樂有兩種可能的同步模式:人類遵循機器的穩定節奏表演,或者機器遵循人類詮釋的音樂節奏表演。前者是最有效的方式,有如卡拉OK,但在此狀況下人類對音樂的詮釋空間相對受限。至於後者,人類可嘗試相對自由的速度詮釋音樂,但機器需要即時計算人類當下演奏的速度以即時跟上,這種技術稱為自動伴奏,儘管已被廣泛研究,但由於音訊特徵在表演現場的多樣性,仍然有很高的挑戰性。
我們處理的自動伴奏系統包含音樂追蹤器(music tracker)、音樂偵測器(music detector)和位置估算單元三個部分。音樂偵測器用於在現場表演啟動系統,而音樂追蹤器包含多執行緒(multi-thread)之線上動態時間校正(ODTW)演算法,每個執行緒估測現場演奏音樂當下的演奏速度,其平均之結果,則是估計的演奏速度,與參照的演奏檔案比較,可得出速度的相對值。最後,位置估算的機制可以讓我們同時追蹤所有目前可能演奏到的位置。結合以上三者可即時算出現場演奏音樂在原譜或參考音檔中的位置,而觸發虛擬音樂家的聲音與動畫內容。在我們的模擬實驗中已驗證本系統的平均延遲(latency)在自然演奏速度下可控制到0.1秒以內。關於本系統之介紹可見影片https://youtu.be/fAFEq8VLO5I。
音樂-肢體動作生成
音樂演奏中的肢體運動大約可分為三種主要類型:帶動樂器產生聲音的器樂動作(instrumental movement)、暗示音樂所表達的情感的表達動作(expressive movement)、以及與其他音樂家合奏/與觀眾互動所需的溝通動作(communicative movement)。這三類動作的建模將有助於根據表演曲目的音樂訊號生成肢體骨架並直接套上動畫角色,而自動產生動畫。我們以從音樂生成小提琴演奏者的動作為目標。此事有趣之處,在於音樂和肢體動作的對應並沒有標準答案,除了個人在表達動作與溝通動作的差異以外,演奏一首曲子的器樂動作也並非唯一:樂譜上通常不規定整個樂曲中每個音的詳細弓指法標註,這使音樂家有很大的自由以根據自己的音樂詮釋安排弓指法。因此如何將音樂對應到合理的換弓點時間,對於視覺/聽覺的整體觀感則至為重要。
是以,我們先是徵集多名小提琴家分別演奏不同風格的曲目,以建立多樣的訓練資料。我們採用3-D動作偵測(pose estimation)技術先偵測骨骼關節的空間做標點作為動作生成的訓練資料。我們提出的網路架構結合預測全身動作的網路以及特別預測右手動作的網路,兩者由所謂的 U 型網路 (U-net) 及自注意力機制 (self-attention) 所構成。此網路的輸入是經過節拍偵測(beat tracking)處理過的每一拍的頻譜資訊,輸出則是目標肢體動作。關於本方法生成的肢體動作與過去方法的比較可見於影片:https://youtu.be/HbxOWn8mc-s。

圖:音樂-視覺風格轉換(music-to-visual style transfer)。此例為將巴比松畫派之配色風格,經由德布西(印象樂派作曲家)之鋼琴作品轉換為印象畫派之風格。
音樂-視覺風格轉換
將音樂內容轉移到視覺風格上,是人工智慧在創造力 (creativity) 研究上的關鍵議題。例如,人類創作者在虛擬實境,動畫和互動藝術中,能夠完美融合視覺和音樂的風格於一體。雖然轉移學習 (transfer learning) 已經是廣受討論的人工智慧技術,也被應用到各種各樣視覺元素甚至是音訊的風格轉換 (style transfer),但幾乎所有進行風格轉換的工作都僅在單一資料模態 (uni-modal) 下運行,例如從圖像到另一圖像,或者從一首曲子到另一曲子。但人類的思考可以輕易跨越數據模態的藩籬,真正的創作往往涉及不同模態資料間的相互作用。本研究為首次探討從音樂到視覺風格的轉換問題。我們的基本假設是音樂和圖像風格可以適當通過它們的共享語義標註 (labels) 進行連結。在音樂與圖像中可以系統性共享的語意標註其實非常稀少,最具規模性的標籤應屬作品所屬的年代。因此,在我們的實驗中,我們收集過去數百年的的古典音樂和繪畫,配對而構成跨模態風格轉換的訓練資料。
我們將音樂-視覺風格的轉換問題分為兩步,期分別為音樂視覺化 (music visualization),即為將音訊資料先轉換為與音訊風格相似的視覺風格元素;以及風格轉換,為一般的圖像風格轉換程序。音樂視覺化網路由一編解碼器網絡結合生成對抗式網路 (GAN) 構成;將音訊特徵輸出風格元素。此網路所生成之圖像則代表音樂所對應到的視覺風格,而和目標圖片一起輸入風格轉換網路。在實驗中,我們觀察到所提出的框架可以從音樂作品中生成可解釋且有意義的圖像風格表示,例如:在印象畫派之後的年代可以見到大量的互補及對比色使用。本工作介紹之影片可見於 https://sunnerli.github.io/Cross-you-in-style/。