為什麼要讓電腦說故事?
說故事 (Storytelling) 是一項古老的人類活動,也是一個測試語言能力的標準方法。一直以來,我們有「說書人」、「作家」這些職業,他們的工作就是產出故事與小說;在學校中,學生們也經常被要求在語言測驗中 (如國文、英文) 講述一個故事,藉以判斷語言學習的效果;很多人都有這樣的經驗經驗,如果要到國外念書,第一關托福或是ESL考試也經常包含說故事、排列故事、或看圖說故事的項目。在這些任務中,如果能夠產生一個好的故事,或稱為「文本」,就算是成功了,也能夠說是具有良好的語言能力。
那麼,在現今人工智慧發達的時代,我們也希望利用人工智慧的技術來「說故事」,一方面,若能說出好的故事,說明人工智慧在語言的表達上,能夠到達一定的技術水準,另一方面,說故事的技術有很多的應用,值得我們深入研究。而說故事的技術,由於關乎文字的分析、理解與生成,屬於「自然語言處理 (Natural Language Processing)」的研究領域。
電腦如何說故事?
做為第一步,我們要先能讓電腦至少說出一個故事。該如何讓電腦說出一個故事呢?讓電腦擁有和人類一樣的能力最直覺的方法,就是讓電腦學習人類工作的方式。記得古代的八股文嗎?簡而言之就是有一些寫作規則,讓寫作文的人可以遵循。在早期,電腦說故事的技術也採取類似的方式,叫做「規則式」或「基於規則」(Rule Based) 的方式。這種方式會事先由程式設計者幫助電腦設定一些規則,例如先講因,再講果,或是一些文法規則,例如被動式可以寫成某A被某B如何了,好讓電腦可以根據這些規則來產生一個故事。然而,這樣的方式效果並不理想,原因在於規則最大的問題就是無法處理所有的情況,要能夠設定能在各種故事中使用的規則,並且將這些規則完美搭配出一個完整的故事,何其容易,因此這樣的故事,總是有堆砌造作的感覺,並且無法通順的行文,看起來並不像人所寫出來的故事。
近年來,由於機器學習與深度學習技術的發展,從資料中學習的說故事技術也開始被廣泛研究,所發展的模型,稱之為「基於資料」或「資料導向」(Data Driven) 模型。這種模型的學習方式,類似於小朋友學習語文,從大量閱讀的文章中,歸納出最常一起出現的字、詞或主題,最後一起產生出來。也可以想像成我們常玩的「故事接龍」遊戲,模型會根據前面已經講的故事內容,預測出最有可能應該往下接的文字,從而生成一個完整的故事。這可以想像成一種聯想性思考,例如說到「龍」的故事,大部分的人都會想到「噴火」的劇情。
然而,要說出一個故事,必須要有形成故事的材料,人類能夠很快說出故事,是因為在成長過程中,有許多生活經驗,學習過許多的知識,因此能夠信手拾穗,文思泉湧。但對於電腦而言,所有的材料都來自於它所看過的資料,因此,有越大量的資料,也就是藉由越多的故事來學習,說故事的能力越強,產生的故事也越通順。然而,電腦所看過的故事,跟人類所知的背景知識相比,還是有所侷限,因此我們可以利用額外的知識幫助電腦撰寫故事,舉例來說,如果我們的知識庫裡面有「人騎馬」的這個知識,那麼當電腦要講人與馬的故事的時候,就能夠說出「一個人正在騎馬」這樣的句子。
除了材料之外,另外一種我們常看到的說故事方式是「看圖說故事 (visual storytelling)」。看圖說故事無論對人或是電腦都是比較困難的任務,因為它將故事發展的空間限制在圖片的內容之中。例如我們剛剛舉的例子,雖然講到龍我們通常聯想到噴火,但是圖片中要是沒有噴火,故事就變得不合理了。這也就是說,電腦要能看圖說故事,除了要具有說故事本身的能力外,還需要具有理解圖片內容的能力,這種多樣化媒體的處理,我們稱為「多模式 (multi-modal)」,通常會包含聲音、影像與文字。分析多模式的混合資料是目前多媒體資訊理解的主流與挑戰。
就算能夠讓電腦說故事,為了技術的改進,我們還要能夠評斷電腦所說的故事內容品質夠不夠好。在國際競賽中判斷電腦故事品質有幾個評分項目可以參考,包括:(1) 是否緊扣主題 (2) 上下文是否通順 (3) 是否願意分享這個故事給朋友 (4) 是否像是人說的故事 (5) 是否有根據 (特別用於自看圖說故事的任務裏) (6) 是否描寫細節。電腦故事品質的自動評分並不可靠,多半仍須依賴真人評分,因此這個技術除了本身開發上的挑戰,在評分上也有一定難度。幸好目前在美國亞馬遜網站平台上有提供「土耳其機器人 (Mechanical Turk)」,也就是線上工人 (真人) 的服務,可以很方便地找到願意協助評估故事品質的人。從評分項目我們也可以看出,自動產生故事時,最大的問題就是多樣化 (diversity) 以及上下文的通順。記得上面我們曾經提到的資料導向的模型嗎?由於電腦產生的故事傾向於說出大部分故事都有的情節,因此經常會產生「我們很開心」、「大家都很開心」這種看似合理但卻有些無趣的故事內容。另外,根據上文所產生的故事下文,經常顧及不到故事邏輯,或是一下子劇情跳躍太遠,這種情況下也會產生奇怪的故事。
我們讓電腦看圖說故事!
中央研究院資訊所的自然語言與情感分析實驗室 (NLPSA Lab),開發了最先進的自動看圖說故事技術,能產生目前最高品質的圖說故事。我們的技術採用深度學習模型,利用大量圖片庫學習抽取圖片的語意,利用這些語意,自動選取連結兩張圖片的最佳知識庫知識,而後結合圖片語意與連結知識,生成故事的劇情概要,這樣的概要能夠幫助之後的模型建構出更加通順的故事。有了劇情概要,我們再利用另外一個利用大量故事訓練出來的,從概要說故事之純文字模型,產生最後的故事。我們的模型,因為先生成了劇情概要,比起一般純粹從資料端學習後直接生成故事的模型,更具有解釋力 (為什麼會產生這樣的故事) 及修改力 (可以修改中間不滿意的部分劇情產生更好的故事)。這樣的功能,在目前電腦故事自動生成技術還無法總是寫出跟人一樣好的故事的情況下,對於故事內容的改進以及後續使用,是非常具有優勢的。
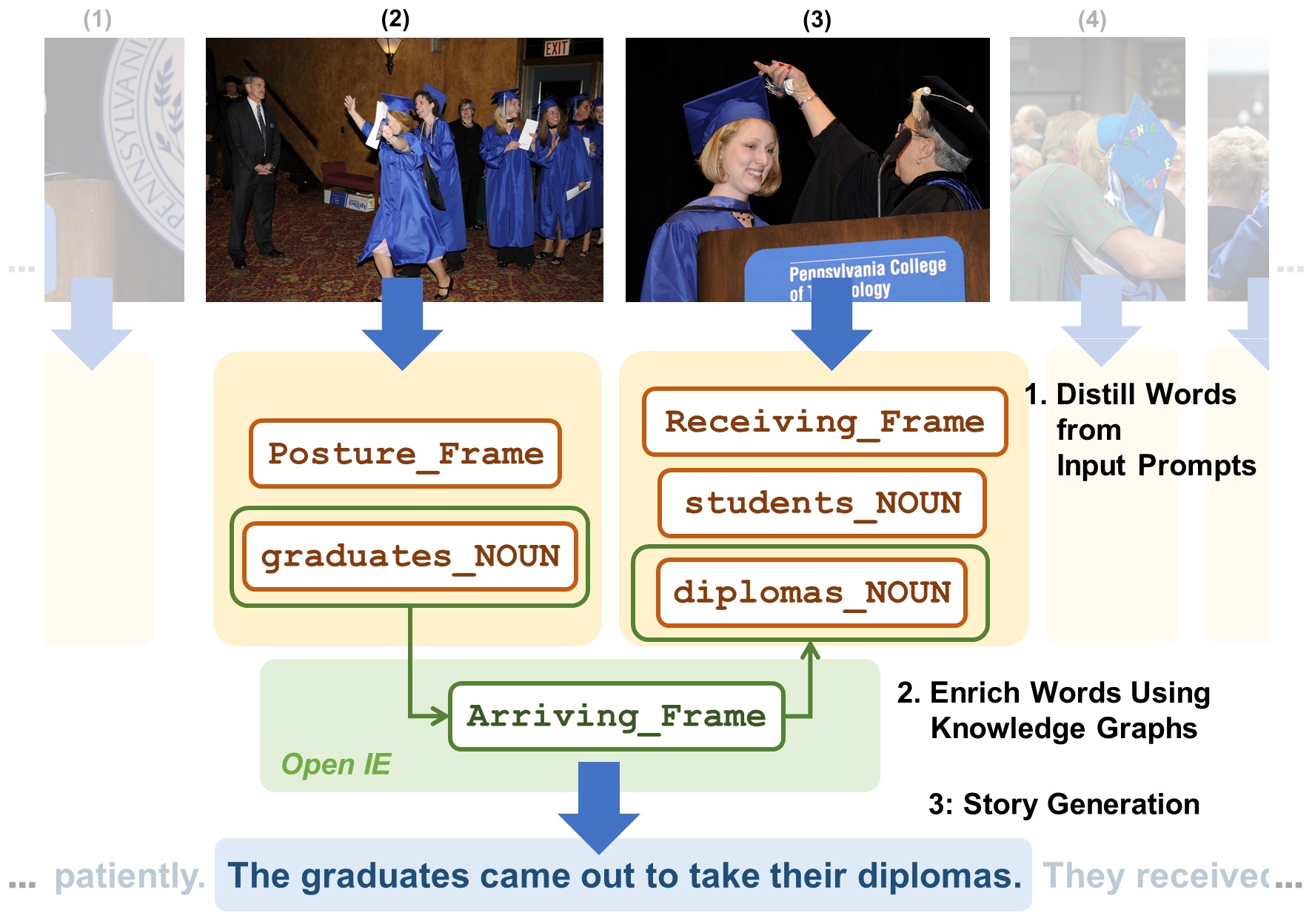
圖一、利用知識庫中畢業生「獲得」證書的這個知識,成功將圖片(2)與圖片(3)連結起來,產生「畢業生出列領取畢業證書」這樣的句子。

圖二、電腦看圖說的三個故事範例。Visual Genome 與 Open IE 分別是我們的模型利用這兩個不同的知識庫提供的知識所產生的故事,No KG是在不添加額外知識時所產生的故事,GLAC是除了我們的模型外目前競賽中效果最好的模型,Human則是人所寫的故事。我們可以看到知識庫的知識的確能幫助故事的上下文連結,另外,人寫的故事包含了許多圖片中沒有的知識。
說故事的應用與未來挑戰
說故事或看圖說故事的技術有很多的應用,一言以蔽之,它能夠快速幫助人們產生各種草稿,節省許多工作時間。例如,我們可以利用這個技術,自動幫我們的相本寫遊記;基於文章的大綱,讓這個技術幫我們寫報告;提供一些優惠條件,讓這個技術幫我們創造廣告文案;如果有幾張畫作,這個技術也能幫我們產生童書或圖畫書。這樣的技術,因為能夠生成各式各樣的故事文本,甚至能夠用來幫助真正的作家尋找靈感,即使電腦的寫作功力還不到位,還需要真正的專家協助潤稿以達到完美。
然而,善與惡的對抗永遠都存在。每一項新科技的出現,都伴隨著危險。故事生成技術的成熟,既已達到「雖不完美,但能理解」的境地,固然節省了許多文字工作者的時間,但也使得許多網路文章靠著這項技術大量產生,導致內容正確性並未,也無法在短時間內進行嚴謹的查核,例如部分內容農場中的文章即屬於此類,而這還是在沒有惡意的情況之下。這項技術,若是有心人加以利用,也可能變成假論文或者是假新聞的產生器,造成嚴重的危害。幸好,許多研究者也注意到了這點,在所開發的自動故事生成模型中,加以些許的調整與轉換,用來判定哪些文章是自動生成,哪些文章是真人撰寫,從而幫助抵抗大量惡意文章的自動生成。
參考論文
Chao-Chun Hsu, Zi-Yuan Chen, Chi-Yang Hsu, Chih-Chia Li, Tzu-Yuan Lin, Ting-Hao Huang, Lun-Wei Ku, “Knowledge-Enriched Visual Storytelling,” in Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI 2020), New York, USA.